
chrome伪装抓取微信公众号内容
前一段时间一直在做微信公众号内容的获取
总结一下,有下面三种方法:
- chrome伪装抓取
- 内存获取方法
- selenium自动爬取法
这篇文章主要是来说明chrome伪装抓取。
抓取前,需要以下工具:
- proxifier+fiddle
- python
- chrome+chromedrive+selenium
proxifier+fiddle主要是用来对微信pc客户端进行抓包,获取cookie和UA,当然也可以通过fiddle抓取手机客户端,方法百度以下就行。
但是由于不想用手机,所以本文采用的是pc端抓包,实现,具体搭建过程,可以参照这位大佬的
然后就是对于微信内置浏览器的模仿了。
第一步,打开需要抓取的微信公众号的,点击历史消息
第二步是通过proxifier+fiddle,抓包。
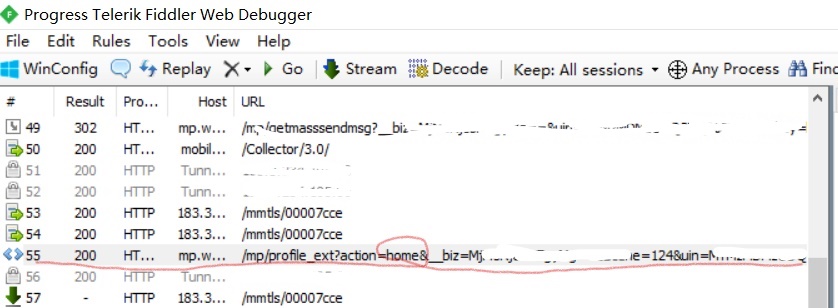
第三步,点击上图的标签,然后如下图
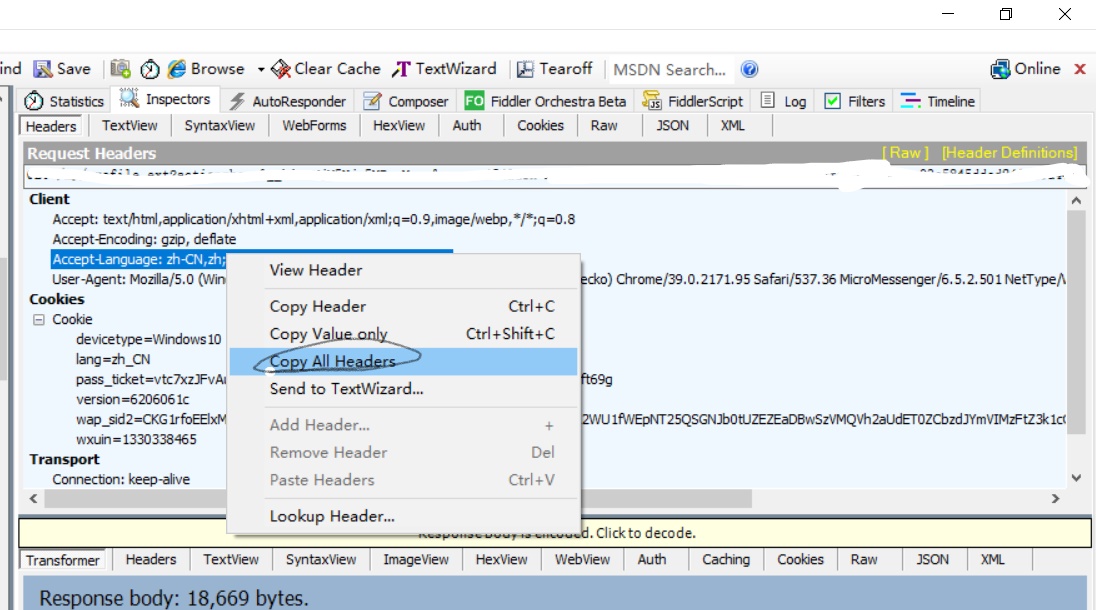
第四步,将复制的东西填进notepad
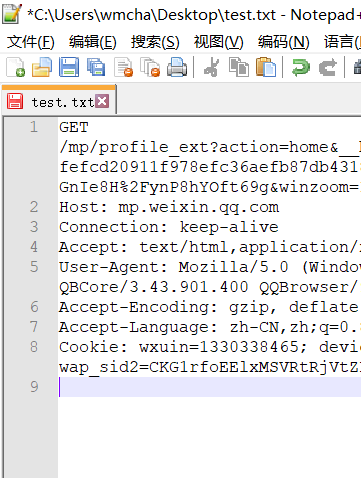
第五步,将user-agent:的内容填入下面的框中。
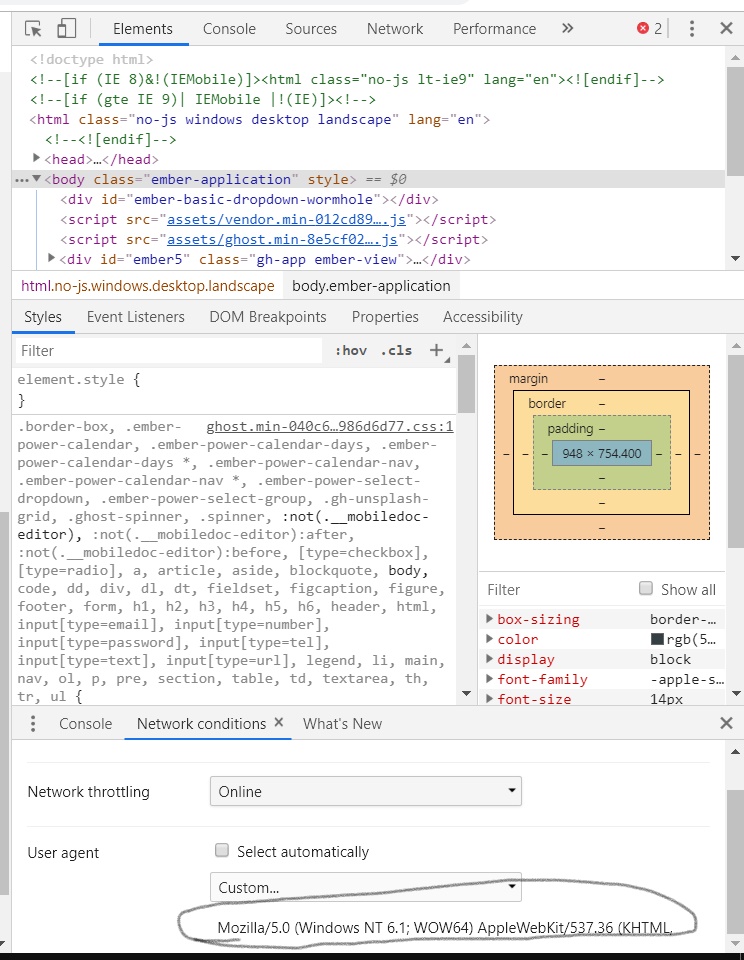
之后点检console,输入document.cookie=”你保存在notepad的cookie”
之后,将第二步点击的url输入chrome中看到类似下图,上面过程,就没有毛病。
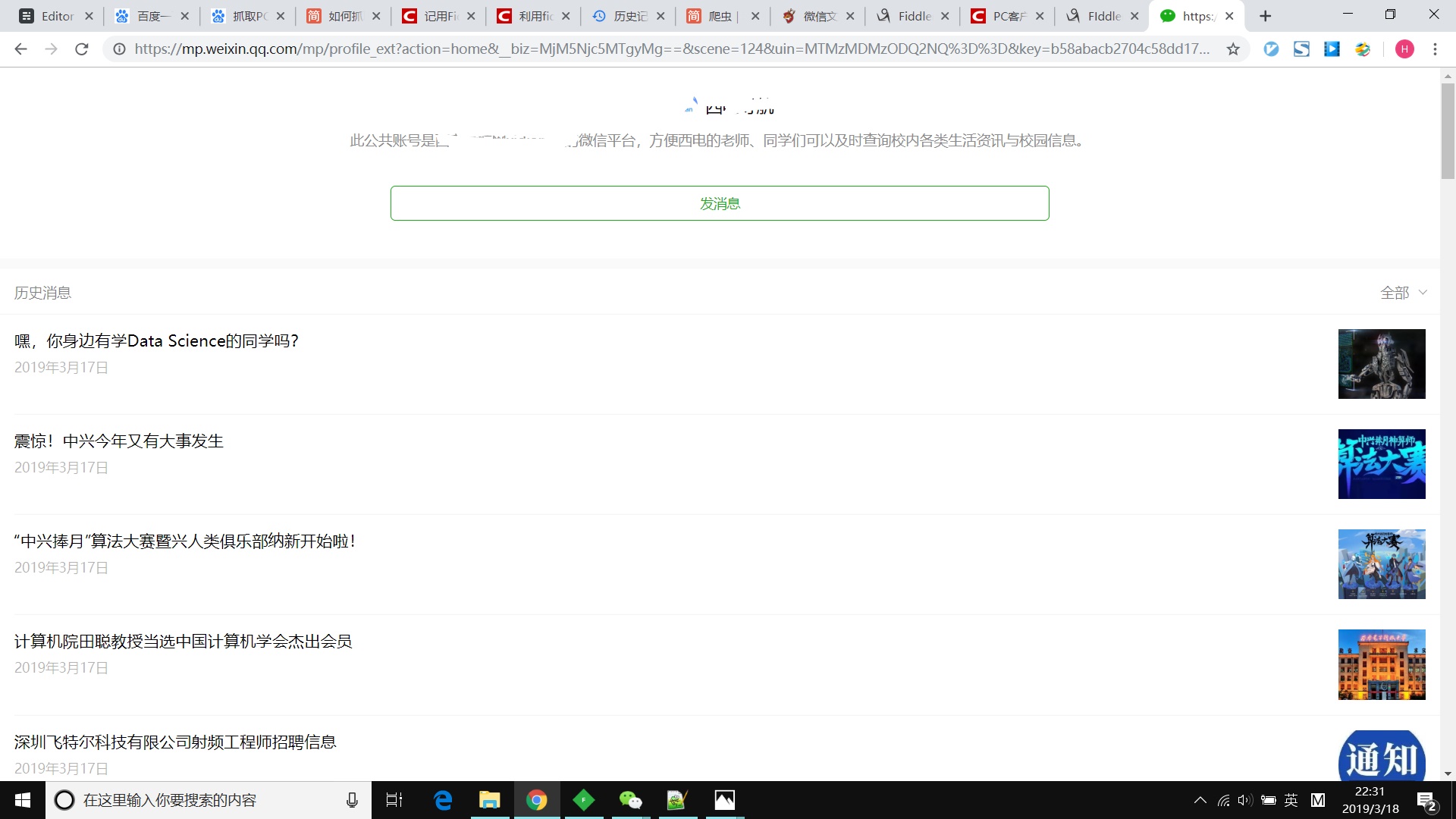
最后就是selenium+chrome+chromedrive+python大显神威了。
至于上面如何用,请自行百度,教程很多。
代码如下:
1 | from selenium import webdriver |
结果如下:
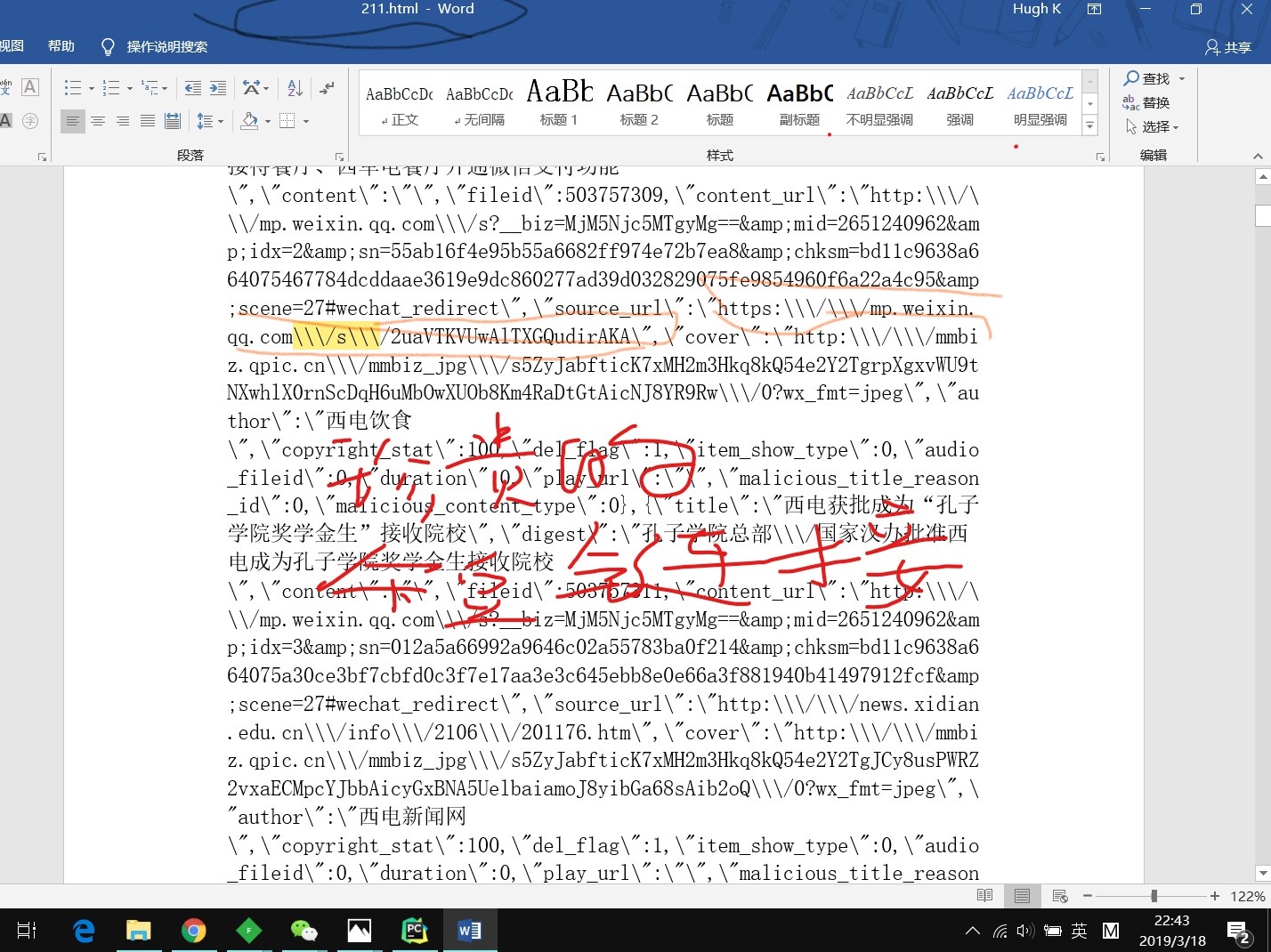
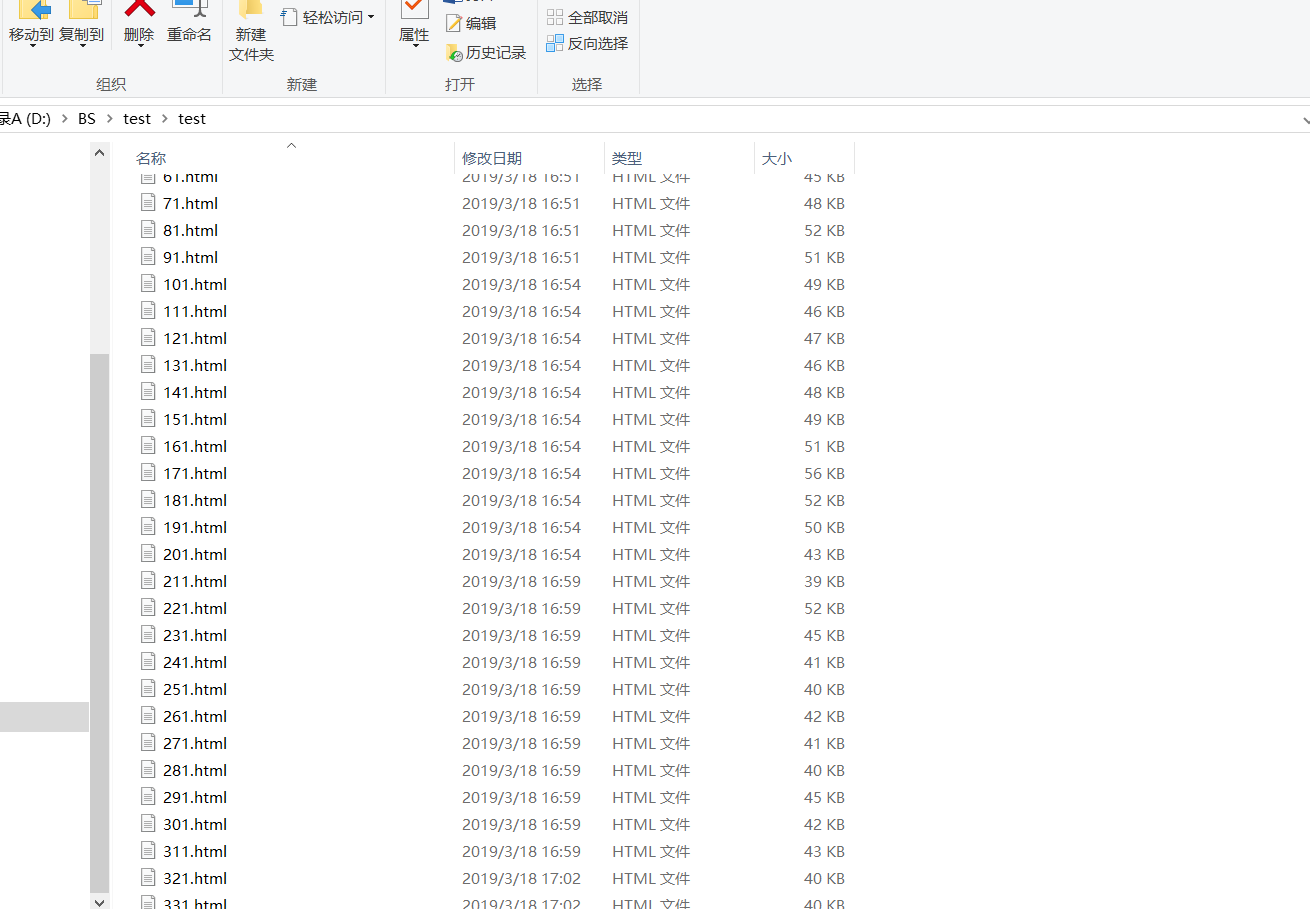
有了html的源码,公众号文章的所有东西都没问题了。
chrome伪装抓取微信公众号内容

